
Best-Practice: Test data procurement
in the context of continuous software development (PART 2/3)
Part 1 of this article dealt with the provisioning of a realistic database for the generation of test data. For this purpose, the current production is regularly copied 1:1. This copy is called a pre-production. Software tests are able to be performed on this database.
PART 2 – Customized test case data for functional, component and regression testing
The further development of an application usually means that different features or even bug fixes need to be implemented. Most of the time, this process involves several developers. Ideally, each feature gets its own environment.
This environment contains only the relevant data for that particular case. Only the test data that is relevant to the new feature is required. Therefore, one will select specific test case data-known contracts, customers, processes, etc. The data is subsequently collected from all systems and databases involved. There are automation tools available that can transfer the respective data completely or partially into the test environment.
Thanks to a versioning option, the test data that’s collected can be used several times without any problems and without influencing the test quality. This means that a backup copy (frozen baseline) is created immediately after the data is made available and before it is used. With the help of this backup, the test environment can always be restored at the push of a button in order to run a test again under the same conditions.
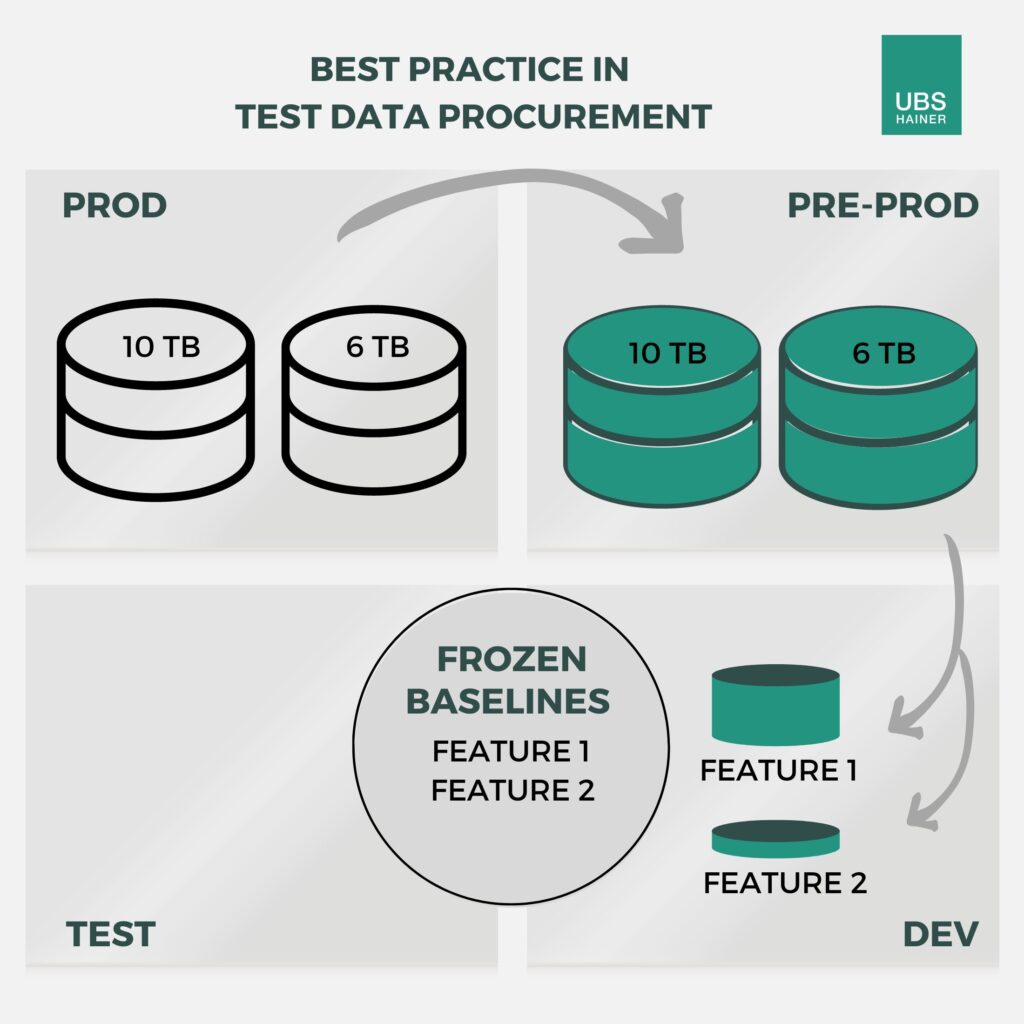
Fig. 1 – In the test environment (DEV), each feature receives its own environment, which only contains the relevant test case data. Before using the data, a backup copy (frozen baseline) can be created. This allows the test case data to be reused as often as needed.
Versioned data can be used later for regression testing
The advantage of such versioned data: They can also be used later for regression testing. These regression tests check whether modifications to parts of the software that were previously tested cause new errors (“regressions”) that subsequently need to be eliminated.
For regression, a separate environment is needed in which one or many tests run regularly for each feature. We group the test case data of a feature into Units. The regression tests should be automated, for example via Continuous Integration or through nightly builds.
The separate regression environment for module and component tests therefore takes in the data from the feature test cases. Over the course of application releases, or over time, the unit environments accumulate a growing pool of valuable tests.
The integration of the finished feature should be done regularly, for example weekly or monthly. Again, a new baseline should be created to jump back to after each test run. When the feature has been completed, the environment in the development area can be cleared.
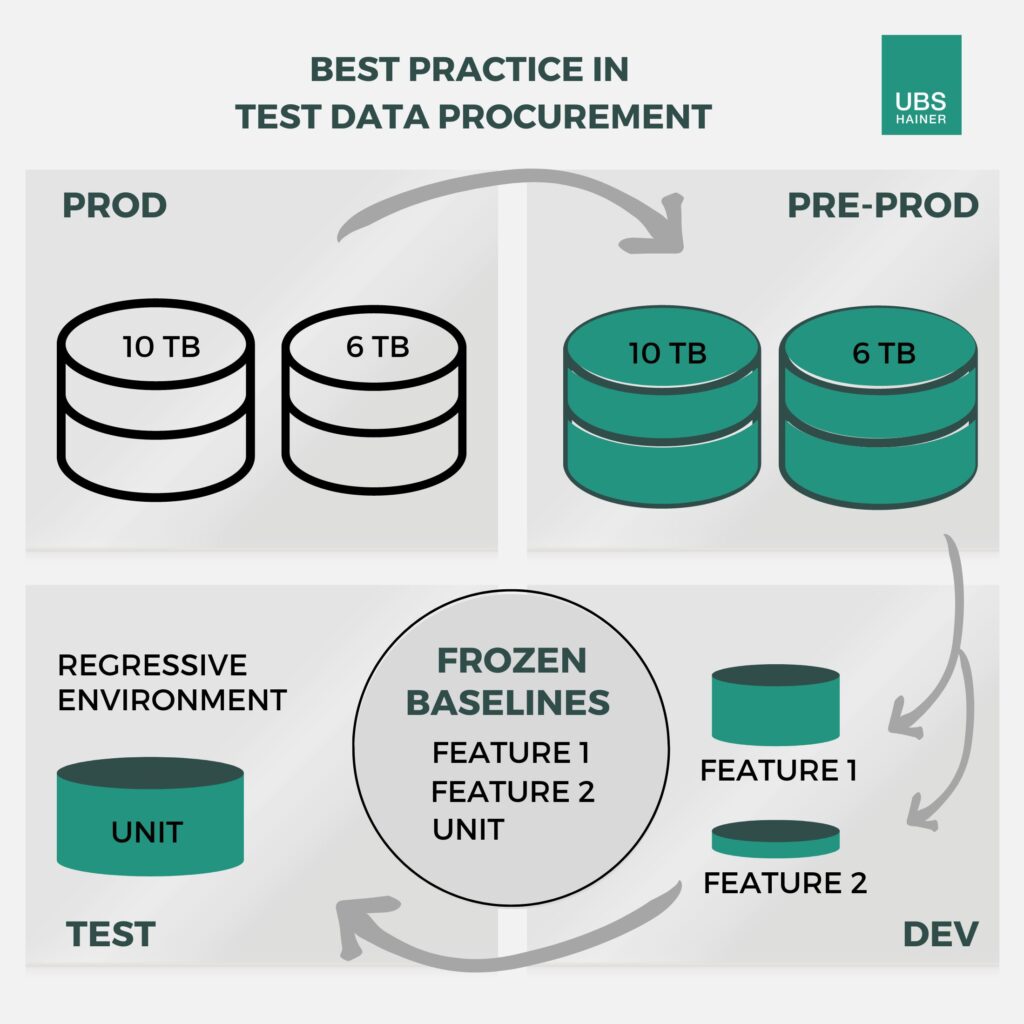 Fig. 2 – All tests of a feature are combined in a unit with which regression tests are continuously performed. A baseline is also created for the unit, which can be used repeatedly.
Fig. 2 – All tests of a feature are combined in a unit with which regression tests are continuously performed. A baseline is also created for the unit, which can be used repeatedly.
Conclusion:
Each software feature is tested in its own development environment with the required test case data. The basic data is saved and reused throughout the process. The test data that is collected for the feature is grouped as a unit and used for regression testing throughout the life cycle of the application.
