
Best-Practice: Test data procurement
in the context of continuous software development (PART 3/3)
Part 1 and Part 2 of this article dealt with the creation of a realistic database for test data through the pre-production. After that, the focus was on the actual development and testing of the individual features. This takes place in a development environment and is followed by regression tests. Next, the feature is removed from the development environment. Before final release, further tests must be performed.
Part 3 – Bulk data for system and release tests
Before the new or modified applications go live, system, release, load or performance tests are applied. For this purpose, no fine-grained customized test case data is needed, but production-related data in larger quantities is required. These tests are usually performed by a separate test group or the QA department in their own environments.
These environments must be provided with current production data on a regular basis, either monthly or even weekly, depending on the cycles in which production updates are performed. For performance and cost reasons, these data renewals are performed – by means of table copy – at table level.
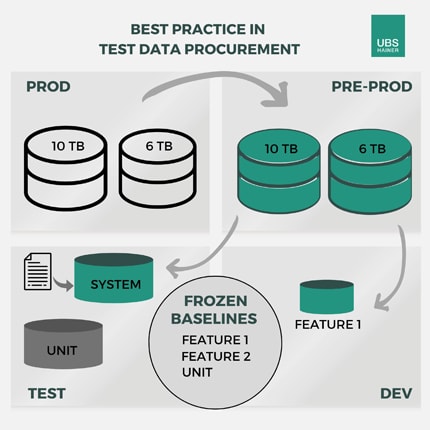
Fig. 1 – To ensure that the new feature works in the live environment, further tests are carried out with new data from preproduction. Table adjustments are documented in a script.
Documentation of structural changes
However, the copied tables still have the data structure of the current productive version. It is possible that this has changed in the current programming. If so, the tables must be adapted to the partially changed structures of the new tables, e.g., by additional columns or changed data types. These structural changes should be centrally documented and best done using a conversion script.
This script is useful in two ways. Firstly, it automates the test data provisioning, i.e. at each further data renewal it automatically brings the data into the correct form. And secondly, it will be needed anyway when the new version goes live. All the better if it has already been used and tested.
In order to obtain an even broader coverage of the mass tests, data from the specific module or component tests can be mixed with production data. Now – as in other environments previously – a baseline should be created. This again serves as a reference data pool to restore the database after running our regression tests.
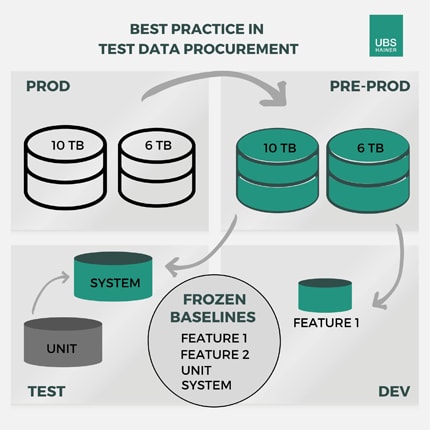
Fig. 2 – The next step is to enhance the mass test data with the unit data. Finally, the system test database is stored as another baseline.
Conclusion:
These approaches allow for extensive testing during the entire development cycle. On the one hand, this applies in an agile context with continuous deployment. On the other hand, the methods shown can also be used in the test phases of a classic development model.
Suitable test data is available in every development phase. Test environments are factually separated. Functional testing and regression are interlocked. A frequent enough renewal of preproduction not only enables testing of the upgrade, but also decouples production and development resp. testing.
With the UBS Hainer TDM Suite, all mentioned processes can be adapted to suit current needs and automated. We would be happy to advise you based on your specific requirements.
