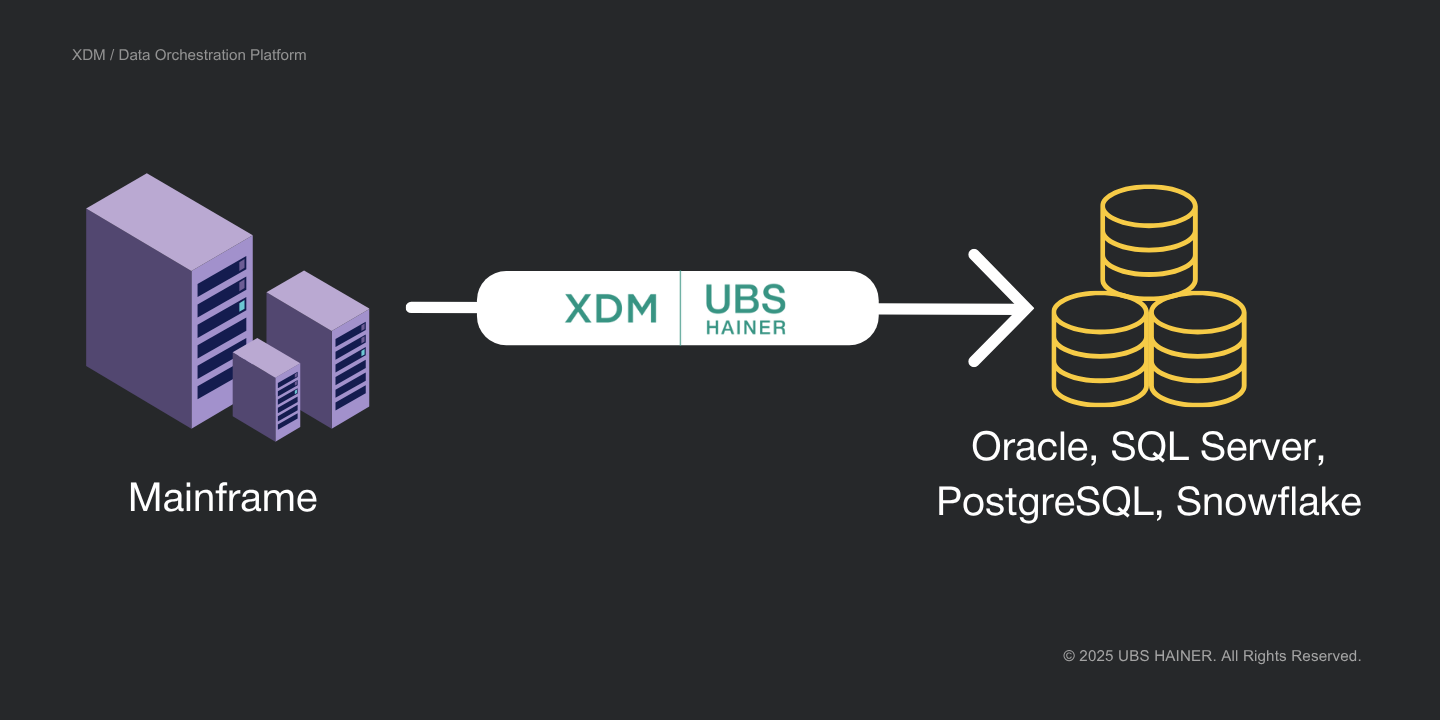
Für viele Großunternehmen unterstützen der Mainframe und die z/OS‑Plattform seit Jahrzehnten geschäftskritische Anwendungen, mit großen Datenmengen in Db2, VSAM oder IMS.
Dieselben Daten werden auf unterschiedliche Weise genutzt – für Entwicklung und Test, in neuen Anwendungen sowie zunehmend für Analytics und KI.
Damit gehen eine Reihe praktischer Herausforderungen einher:
- Wie kann sichergestellt werden, dass Daten zuverlässig in unterschiedlichen Systemen genutzt werden können?
- Wie werden die Komplexität und die Besonderheiten der verschiedenen Datenquellen gehandhabt?
- Wie können Teams neue Anwendungen effektiv mit aktuellen, produktionsähnlichen Daten testen?
- Wie wird die Einhaltung von Datenschutzvorgaben im gesamten Prozess sichergestellt?
Datenbewegungen während der Migration
Um diese Anforderungen zu unterstützen, etablieren Unternehmen typischerweise mehrere Nutzungspfade für ihre Daten.
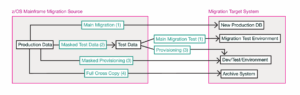
Testdatenbereitstellung
Eine zentrale Anforderung ist die Fähigkeit, konsistente, produktionsähnliche Daten für Entwicklung und Test bereitzustellen.
Dazu werden relevante Datensätze aus Produktionssystemen extrahiert, ihre Beziehungen erhalten und in Testumgebungen bereitgestellt. Gleichzeitig müssen sensible Informationen geschützt werden – Maskierung oder Anonymisierung sind daher ein integraler Bestandteil des Prozesses.
Solche Datensätze ermöglichen es Teams, Anwendungen sicher zu entwickeln und zu validieren, ohne Produktionsdaten offenzulegen.
Datenkopien für Entwicklung, Analytics und KI
Über Tests hinaus werden häufig Datenteilmengen für Entwicklungsarbeiten, Analytics und KI‑Anwendungsfälle benötigt.
In diesen Szenarien steht die Auswahl relevanter Datensätze im Vordergrund, die reale Geschäftsprozesse widerspiegeln. So kann mit realitätsnahen Daten gearbeitet werden, während das Datenvolumen beherrschbar bleibt und auf den jeweiligen Use Case zugeschnitten ist.
Datentransfer für neue Systeme
In manchen Fällen werden Daten zur Unterstützung neuer Systeme übertragen.
Dies kann schrittweise oder in einmaligen Transfers von Produktionsdaten erfolgen, teilweise mit Anpassungen in Struktur oder Format. Der Fokus liegt darauf, Daten für einen neuen Kontext aufzubereiten.
Archivierung
Eine vollständige Kopie eines Datensatzes kann auch zu Archivierungszwecken erstellt werden.
So können Organisationen einen historischen Schnappschuss ihrer Daten aufbewahren – für Audits, zur Referenz oder für einen späteren Zugriff – auch wenn sich Systeme weiterentwickeln.
Die Komplexität von Mainframe-Daten
Die Arbeit mit Mainframe-Daten in diesen Szenarien ist von Natur aus komplex.
Daten sind häufig eng mit Geschäftsprozessen verknüpft, über mehrere Systeme verteilt und für transaktionsorientierte Verarbeitung strukturiert. Das Extrahieren und Wiederverwenden erfordert sorgfältige Handhabung, um Konsistenz und Vollständigkeit zu bewahren. Einfache Kopien können zu gebrochenen Beziehungen oder unvollständigen Datensätzen führen.
Darüber hinaus führt jede Nutzung von Produktionsdaten außerhalb des Quellsystems zu strengen Anforderungen in den Bereichen Sicherheit und Compliance.
Datenmaskierung und Compliance
Immer wenn Produktionsdaten außerhalb ihres Ursprungssystems genutzt werden, ist der Schutz sensibler Informationen entscheidend.
Personenbezogene und geschäftskritische Daten müssen so anonymisiert oder maskiert werden, dass Konsistenz erhalten bleibt und die Daten dennoch für Tests, Analytics oder Entwicklung nutzbar sind. In regulierten Umgebungen ist dies eine grundlegende Voraussetzung.
XDM als Lösung für Datenbereitstellung und Testdatenmanagement
XDM unterstützt eine strukturierte Datenbereitstellung und ein laufendes Testdatenmanagement in Mainframe‑ und verteilten Umgebungen.
- Plattformübergreifende Datenextraktion und -beladung
XDM unterstützt Mainframe‑Quellen wie Db2 for z/OS, VSAM und IMS sowie Zielplattformen wie Oracle, SQL Server, PostgreSQL, Snowflake und andere. Daten können systemübergreifend übertragen werden, wobei Formate und Datentypen automatisch konvertiert werden. Das reduziert manuellen Aufwand und Projektkomplexität. - Automatisierter Umgang mit Strukturunterschieden
Systeme unterscheiden sich oft in ihrer Struktur – etwa durch neue oder fehlende Felder, umbenannte Tabellen oder abweichende Datentypen. XDM erkennt diese Unterschiede und wendet Mapping‑Regeln an, generiert bei Bedarf DDL für das Zielsystem und unterstützt Transformationen während der Bereitstellung. - Integrierte Datenmaskierung und Anonymisierung
Die Nutzung von Produktionsdaten in Nicht‑Produktivumgebungen erfordert einen angemessenen Schutz sensibler Informationen. XDM stellt eine Reihe von Verfahren zur Datenmaskierung bereit, die konsistent über Datensätze hinweg angewendet werden können. Wo erforderlich, kann zusätzlich synthetische Datengenerierung genutzt werden, um Datenschutzanforderungen zu erfüllen. - Workflow‑Automatisierung und Self‑Service‑Testdatenbereitstellung
XDM ermöglicht Ende‑zu‑Ende‑Provisioning‑Workflows – von der Datenauswahl und Maskierung bis zur Bereitstellung in der Zielumgebung. Anwender können Testdaten über eine Weboberfläche anfordern und bereitstellen, ohne direkten Zugriff auf die Quellsysteme zu benötigen. - Monitoring und Nachvollziehbarkeit
Alle Schritte der Datenbereitstellung werden protokolliert und sind nachvollziehbar. Dies schafft Transparenz darüber, welche Daten wann und wie verarbeitet wurden, und unterstützt sowohl den operativen Überblick als auch Compliance‑Anforderungen.
Fazit
Die Nutzung von Daten über mehrere Anwendungsfälle hinweg erfordert einen strukturierten Ansatz für Datenbereitstellung und ‑wiederverwendung.
XDM unterstützt dies, indem es konsistente, maskierte und wiederholbar erzeugbare Datensätze über Umgebungen hinweg ermöglicht und Organisationen erlaubt, ihre Daten dort einzusetzen, wo sie benötigt werden – bei gleichzeitiger Wahrung von Stabilität und Kontrolle in den produktiven Systemen.
