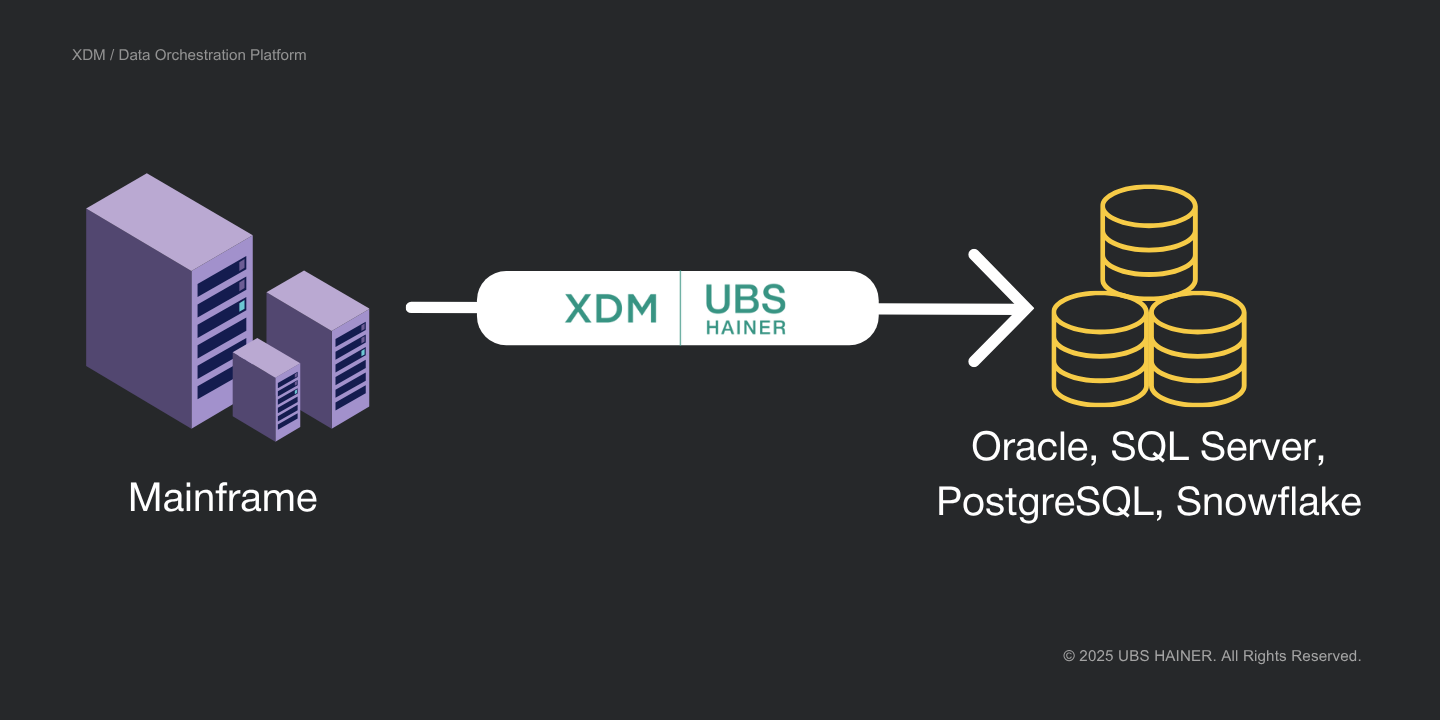
For many large enterprises, the mainframe and z/OS platform have supported business-critical applications for decades, with large volumes of data stored in Db2, VSAM, or IMS.
That same data is used in different ways—for development and testing, in new applications, and increasingly for analytics and AI.
This brings a number of practical challenges:
- How can data be reliably used across different systems?
- How do you handle the complexities and special characteristics of various data sources?
- How can teams effectively test new applications using current, production-like data?
- How is compliance with data protection regulations ensured throughout the process?
Data Usage Pathways
To support these needs, organizations typically establish several data usage pathways.
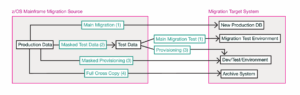
Test Data Provisioning
A key requirement is the ability to provide consistent, production-like data for development and testing.
This involves extracting relevant datasets from production systems, preserving their relationships, and provisioning them into test environments. At the same time, sensitive information must be protected, making masking or anonymization an integral part of the process.
Such datasets allow teams to safely develop and validate applications without exposing production data.
Data Copies for Development, Analytics, and AI
Beyond testing, subsets of data are often needed for development work, analytics, and AI use cases.
These scenarios focus on selecting relevant datasets that reflect real business processes. This makes it possible to work with realistic data while keeping volumes manageable and aligned with the specific use case.
Data Transfer for New Systems
In some cases, data is transferred to support new systems.
This may involve phased or one-time transfers of production data, sometimes with adjustments to structure or format. The focus is on preparing data for a new context.
Archival
A full copy of a dataset may also be created for archival purposes.
This allows organizations to retain a historical snapshot of their data—for audit, reference, or later access—even as systems evolve.
The Complexity of Mainframe Data
Working with mainframe data across these scenarios is inherently complex.
Data is often tightly coupled to business processes, distributed across multiple systems, and structured for transaction processing. Extracting and reusing it requires careful handling to maintain consistency and completeness. Simple copies can lead to broken relationships or incomplete datasets.
In addition, any use of production data outside its source system introduces strict security and compliance requirements.
Data Masking and Compliance
Whenever production data is used beyond its source system, protecting sensitive information becomes essential.
Personal and business-critical data must be anonymized or masked in a way that preserves consistency while remaining usable for testing, analytics, or development. In regulated environments, this is a fundamental requirement.
XDM as a Solution for Data Provisioning and Test Data Management
XDM supports structured data provisioning and ongoing test data management across mainframe and distributed environments:
- Cross-Platform Data Extraction and Loading
XDM supports mainframe sources such as Db2 for z/OS, VSAM, and IMS, as well as target platforms including Oracle, SQL Server, PostgreSQL, Snowflake, and others. Data can be transferred across system boundaries with automatic conversion of formats and data types, reducing manual effort and project complexity. - Automated Handling of Structural Differences
Systems often differ structurally—for example through new or missing fields, renamed tables, or different data types. XDM identifies these differences and applies mapping rules, generates target DDL where needed, and supports transformations during provisioning. - Integrated Data Masking and Anonymization
Using production data in non-production environments requires appropriate protection of sensitive information. XDM provides a range of data masking methods that can be applied consistently across datasets. Where needed, synthetic data can also be generated to support data protection requirements. - Workflow Automation and Self-Service Test Data Provisioning
XDM enables end-to-end provisioning workflows—from data selection and masking to delivery in the target environment. Users can request and provision test data through a web interface without requiring direct access to source systems. - Monitoring and Auditability
All data provisioning steps are logged and can be reviewed. This provides transparency into what data was processed, when, and how, supporting both operational oversight and compliance requirements.
Conclusion
Working with data across multiple use cases requires a structured approach to data provisioning and reuse.
XDM supports this by enabling consistent, masked, and repeatable datasets across environments, allowing organizations to use their data where it is needed while maintaining stability and control in production systems.
