
Best-Practice: Testdatenbeschaffung
im Rahmen kontinuierlicher Software-Entwicklung (TEIL 3/3)
Teil 1 und Teil 2 dieser Reihe befassten sich mit der Schaffung einer realitätsnahmen Datenbasis für Testdaten durch die Pre-Production. Dann ging es um die eigentliche Entwicklung und das Testen der einzelnen Features in der Entwicklungsumgebung samt Regressionstests. Damit ist die Entwicklung zunächst abgeschlossen und das Feature wird aus der Entwicklungsumgebung entfernt. Vor der endgültigen Abnahme folgen jetzt noch weitere Tests.
Part 3 – Bulk data for system and release tests
Bevor die neuen oder modifizierten Applikationen live gehen, kommen abschließend System-, Abnahme-, Last- oder Performancetests zur Anwendung. Hier braucht es keine feinkörnigen maßgeschneiderten Testfalldaten, sondern produktionsnahe Daten in größeren Mengen. Diese Tests werden in der Regel von einer separaten Testgruppe oder der QS Abteilung in eigenen Umgebungen durchgeführt.
Diese Umgebungen müssen in regelmäßigen Abständen mit aktuellen Produktionsdaten versorgt werden. Entweder monatlich oder sogar wöchentlich, je nachdem, in welchen Zyklen Produktionsupdates durchgeführt werden. Aus Performance- und Kostengründen werden diese Datenerneuerungen – mittels Tabellenkopie – auf Tabellenebene durchgeführt.
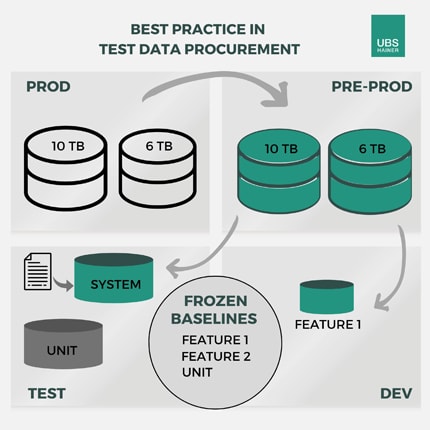
Abb. 1 – Um sicherzustellen, dass das neue Feature in der live Umgebung funktioniert, werden weitere Tests mit neuen Daten aus der Preproduction durchgeführt. Tabellen-Anpassungen werden dabei in einem Script dokumentiert.
Dokumentation der Strukturänderungen
Die kopierten Tabellen haben jedoch die Datenstruktur der aktuell produktiven Version. Eventuell hat sich diese jedoch in der aktuellen Programmierung geändert. Also müssen die Tabellen an die teils geänderten Strukturen der neunen – im Test befindlichen – Tabellen angepasst werden, z. B. durch zusätzliche Spalten oder geänderte Datentypen. Diese Strukturänderungen sollten zentral dokumentiert sein und am besten durch ein Umstellungsskript erledigt werden.
Dieses Skript ist in zweifacher Hinsicht nützlich. Erstens automatisiert es die Testdatenbereitstellung, d. h. bei jeder weiteren Datenerneuerung bringt es die Daten automatisch in die richtige Form. Und zweitens wird es bei der Indienststellung – Go-Live – der neuen Version ohnehin gebraucht. Umso besser, wenn es schon benutzt und damit getestet wurde.
Um nun eine noch breitere Abdeckung der Massentests zu erhalten, können die Daten der spezifischen Modul- bzw. Komponententests mit den Daten aus der Produktion gemischt werden. Nun sollte – wie auch in anderen Umgebungen zuvor – eine Baseline erstellt werden. Diese dient wieder als Referenzbestand, um nach der Durchführung unserer Regressionstest den Ausgangsbestand wiederherzustellen.
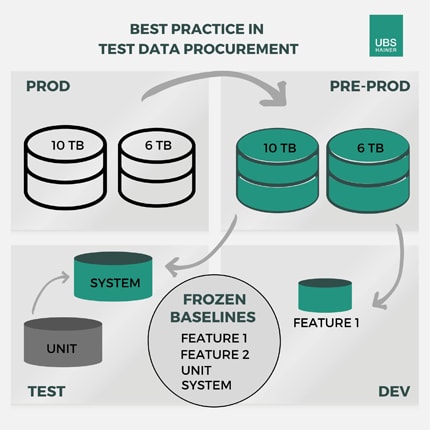
Abb. 2 – Als weitere Stufe werden die Daten der Massentests durch die Unit-Daten erweitert. Am Ende wird der Datenbestand der Systemtests als weitere Baseline gespeichert.
Fazit:
Die bisher gezeigten Ansätze erlauben umfangreiche Tests während des kompletten Entwicklungszyklus. Neben der Betrachtung in einem agilen Kontext mit Continious Deployment lassen sich die hier gezeigten Verfahren auch in einem klassischen Entwicklungsmodell in den Testphasen nutzen.
Es stehen in jeder Entwicklungsphase geeignete Testdaten zur Verfügung. Testumgebungen sind sachlich getrennt. Funktionstest und Regression sind verzahnt. Eine häufig genug erneuerte Pre-Production ermöglicht nicht nur das Testen der Versions-Änderung – des Upgrades also –, sondern entkoppelt auch Produktion und Entwicklung bzw. Test.
Mit der UBS Hainer TDM Suite können alle hier angesprochenen Prozesse an die aktuellen Bedürfnisse angepasst und automatisiert werden. Wir beraten Sie gern anhand Ihrer konkreten Anforderungen.
