
Best-Practice: Testdatenbeschaffung
im Rahmen kontinuierlicher Software-Entwicklung (TEIL 2/3)
Teil 1 dieser Reihe befasste sich mit der Bereitstellung einer realitätsnahen Datenbasis, um daraus Testdaten zu generieren. Dazu wird regelmäßig die aktuelle Produktion 1:1 kopiert. Diese Kopie wird als Pre-Production bezeichnet. Mit dieser Datenbasis kann jetzt das Software-Testing durchgeführt werden.
TEIL 2 - Maßgeschneiderte Testfalldaten für Funktions-, Komponenten- und Regressionstests
In der Regel bedeutet die Weiterentwicklung einer Anwendung, dass unterschiedliche Features oder auch Bug Fixes zu implementieren sind. Meist sind mehrere Entwickler beteiligt. Im Optimalfall erhält jedes Feature eine eigene Umgebung.
Diese Umgebung enthält nur die relevanten Daten für den jeweiligen Fall. Es sind nur die Testdaten erforderlich, die für das neue Feature von Interesse sind. Dazu wird man spezifische Testfalldaten zum Beispiel bekannte Verträge, Kunden, Vorgänge o. ä. selektieren. Auch hier gibt es Automation-Tools, die die jeweils abhängigen Daten komplett oder teilweise in die Test-Umgebung überführen. Dazu werden diese aus allen beteiligten Systemen und Datenbanken zusammengetragen.
Durch eine Versioning-Option können diese sogar problemlos mehrfach genutzt werden, ohne die Testqualität zu beeinflussen. Dabei wird direkt nach der Bereitstellung der Daten und vor ihrer Nutzung eine Sicherungskopie (Frozen Baseline) erstellt. Mithilfe dieser Sicherung kann die Testumgebung auf Knopfdruck immer wieder hergestellt werden, um einen Test von Neuem unter gleichen Bedingungen durchzuführen.
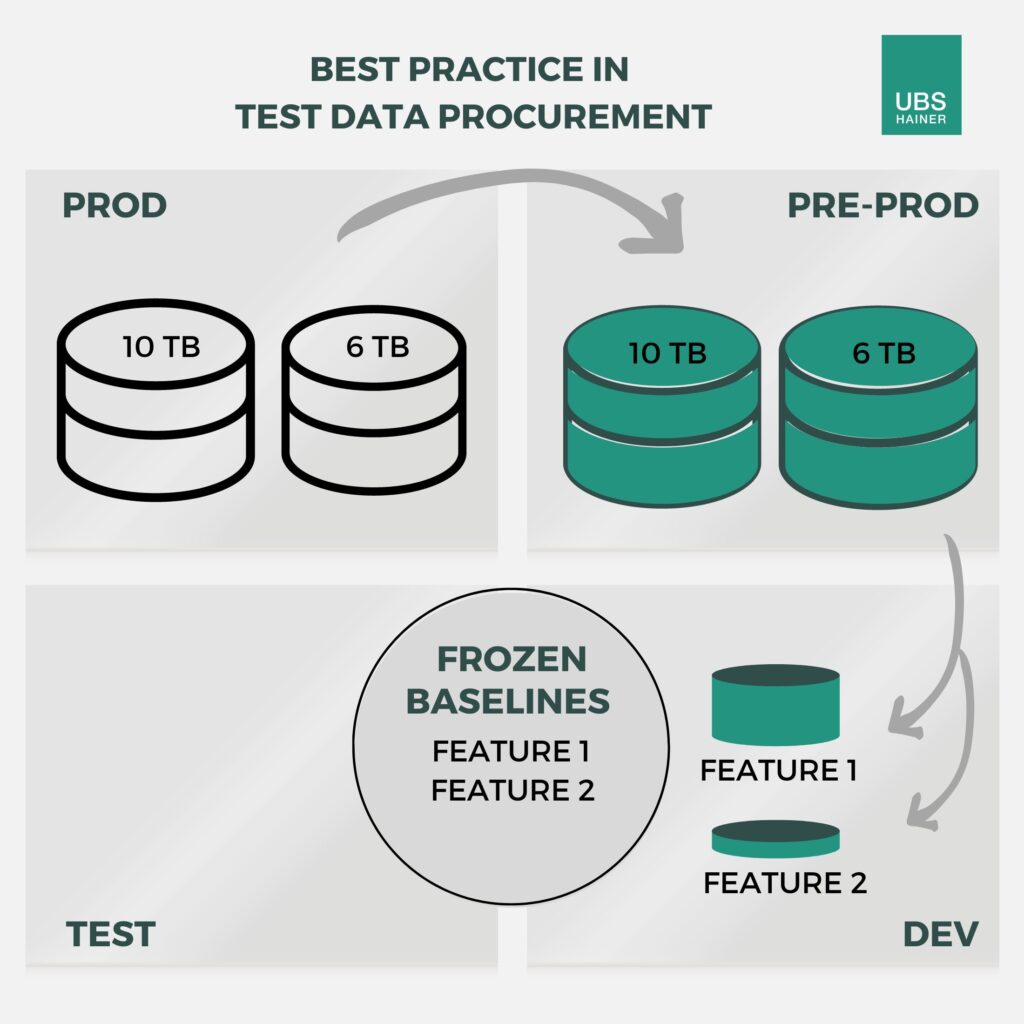
Abb. 1 – In der Testumgebung (DEV) erhält jedes Feature eine eigene Umgebung, die auch nur die dafür relevanten Testfalldaten enthält. Vor der Verwendung der Daten kann eine Sicherungskopie (Frozen Baseline) erstellt werden. Damit können die Testfalldaten beliebig oft wiederverwendet werden.
Versionierte Daten später für Regressionstests nutzen
Der Vorteil solcher versionierten Daten: Diese können später auch für die Regressionstests genutzt werden. Dabei wird geprüft, ob Modifikationen in bereits getesteten Teilen der Software neue Fehler („Regressionen“) verursachen, die beseitigt werden müssen.
Für die Regression wird dann eine eigene Umgebung benötigt, in der für jedes Feature ein bis viele Tests regelmäßig laufen. Wir fassen die Testfalldaten eines Features hier unter Units zusammen. Die Regressionstests sollten automatisiert durchgeführt werden, beispielsweise über Continuous Integration oder durch Nightly Builts.
Die separate Regressionsumgebung für Modul- und Komponententests nimmt also die Daten der Testfälle der Features auf. Über die Anwendungs-Releases bzw. über die Zeit hinweg reichern sich dann Unit-Umgebungen mit einem wachsenden Fundus an wertvollen Tests an.
Das Integrieren vom fertigen Feature sollte regelmäßig zum Beispiel wöchentlich oder monatlich geschehen. Danach sollte auch hier wieder eine neue Baseline erstellt werden, zu der nach jeder Testdurchführung zurückgesprungen wird. Wenn das Feature fertiggestellt wurde, kann die Umgebung im Entwicklungsbereich freigegeben werden.
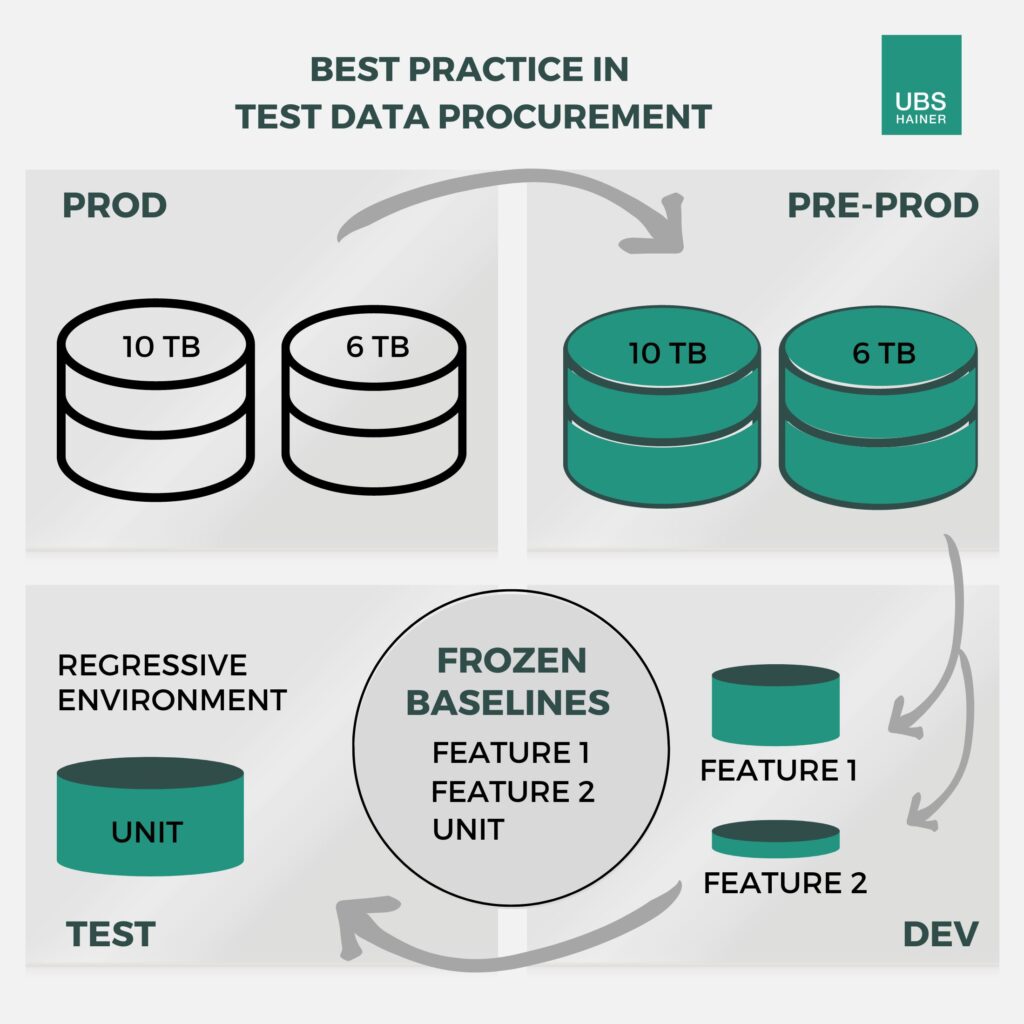 Abb. 2 – Alle Test eines Features werden in einer Unit zusammengefasst, mit der kontinuierlich Regressionstest durchgeführt werden. Auch für die Unit wird eine Baseline erstellt, auf die immer wieder zurückgegriffen werden kann.
Abb. 2 – Alle Test eines Features werden in einer Unit zusammengefasst, mit der kontinuierlich Regressionstest durchgeführt werden. Auch für die Unit wird eine Baseline erstellt, auf die immer wieder zurückgegriffen werden kann.
Fazit:
Jedes Software-Feature wir in einer eigenen Entwicklungsumgebung mit den dafür benötigten Testfalldaten getestet. Die grundlegenden Daten werden gesichert und im Prozess immer wiederverwendet. Die gesammelten Testdaten des Features werden als Unit zusammengefasst und für Regressionstest im weiteren Lebenszyklus der Applikation genutzt.
